
Learn About MEG and Electromagnetic Brain Mapping at the Medical College of Wisconsin
Data Preprocessing
Data filtering is a conceptually simple, though powerful technique to extract signals within a predefined frequency band of interest. This off-line data pre-processing step is the realm of digital filtering: an important and sophisticated subfield of electrical engineering (Hamming, 1983). Applying a filter to the data presupposes that the information carried by signals will be mostly preserved, to the benefit of attenuating other frequency components of supposedly, no interest.
Not every digital filter is suitable to the analysis of MEG/EEG traces. Indeed, the performances of filters are defined from basic characteristics such as the attenuation outside the bandpass of the frequency response, stability, computational efficiency and most importantly, the introduction of phase delays. This latter is a systematic by-product of filtering and some filters may be particularly inappropriate in that respect: infinite impulse response (IIR) digital filters are usually more computationally efficient than finite impulse response (FIR) alternatives, but with the inconvenient of introducing non-linear frequency-dependent phase delays; hence some non-equal delays in the temporal domain at all frequencies, which is unacceptable for MEG/EEG signal analysis where timing and phase measurements are crucial. FIR filters delay signals in the time domain equally at all frequencies, which can be conveniently compensated for by applying the filter twice: once forward and once backward on the MEG/EEG time series (Oppenheim, Schafer, & Buck, 1999).
Note however some possible edge effects of the FIR filter at the beginning and end of the time series, and the necessity of a large number of time samples when applying filters with low high-pass cutoff frequencies (as the length of the filter’s FIR increases). Hence it is generally advisable to apply digital high-pass filters on longer episodes of data, such as on the original ‘raw’ recordings, before these latter are chopped into epochs of shorter durations about each trial for further analysis.
Bringing more details to the discussion would reach outside the scope of these pages. The investigator should nevertheless be well aware of the potential pitfalls of analysis techniques in general, and of digital filters in particular. Although commercial software tools are well equipped with adequate filter functions, in-house or academic software solutions should be first evaluated with great caution.
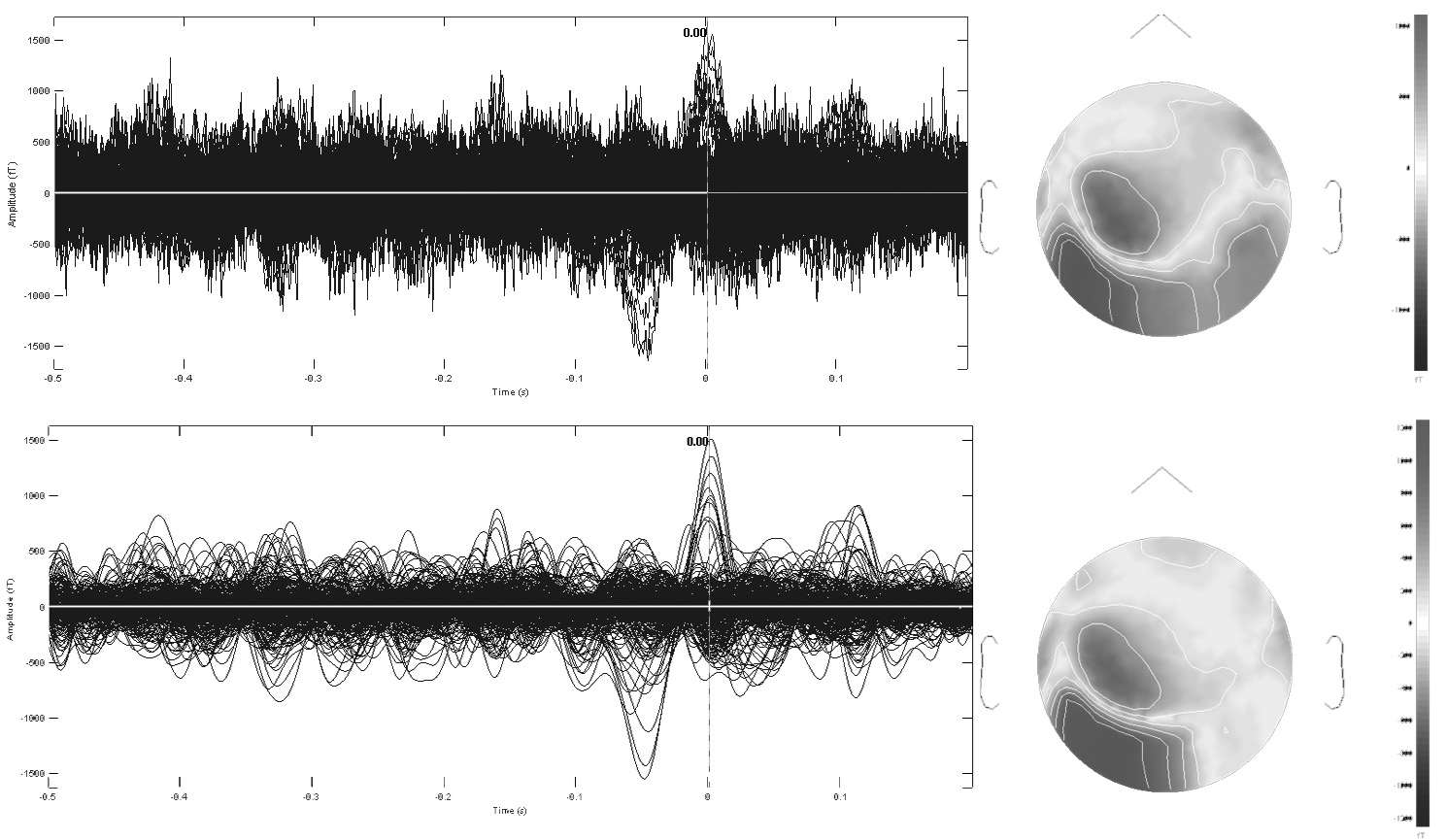
Digital band-pass filtering applied to spontaneous MEG data during an interictal epileptic spike event (total epoch of 700ms duration, sampled at 1KHz). The time series of 306 MEG sensors are displayed using a butterfly plot, whereby all waveforms are overlaid within the same axes. The top row displays the original data with digital filters applied during acquisition between 1.5 and 330Hz. The bottom row is a pre-processed version of the same data, band-passed filtered between 2 and 30Hz. Note how this version of the data better reveals the epileptic event occurring about time t=0ms. The corresponding sensor topographies of MEG measures are displayed to the right. The gray scale display represents the intensity of the magnetic field captured at each sensor location and interpolated over a flattened version of the MEG array (nose pointing upwards). Note also how digital band-pass filtering strongly alters the surface topography of the data, by revealing a simpler dipolar pattern over the left temporo-occipital areas of the array.
An enduring tradition of MEG/EEG signal analysis consists in enhancing brain responses that are evoked by a stimulus or an action, by averaging the data about each event – defined as an epoch – across trials. The underlying assumption is that there exist some consistent brain responses that are time-locked and so-called 'phase-locked' to a specific event (again e.g., the presentation of a stimulus or a motor action).
Hence, it is straightforward to enhance these responses by proceeding to epoch averaging across trials, under the assumption that the rest of the data is inconsistent in time or phase with respect to the event of interest. This simple practice has permitted a vast amount of contributions to the field of event-related potentials (in EEG, ERP) and fields (in MEG, ERF) (Handy, 2004, Niedermeyer & Silva, 2004).
Trial averaging necessitates that epochs be defined about each event of interest (e.g. the stimulus onset, or the subject’s response, etc.). An epoch has a certain duration, usually defined with respect to the event of interest (pre and post-event). Averaging epochs across trials can be conducted for each experimental condition at the individual and the group levels. This latter practice is called ‘grand-averaging’ and has been made possible originally because electrodes are positioned on the subject’s scalp according to montages, which are defined with respect to basic, reproducible geometrical measures taken on the head. The international 10-20 system was developed as a standardized electrode positioning and naming nomenclature to allow direct comparison of studies across the EEG community (Niedermeyer & Silva, 2004). Standardization of sensor placement does not exist in the MEG community, as the sensor arrays are specific to the device being used and subject heads fit differently under the MEG helmet.
Therefore, grand or even inter-run averaging is not encouraged in MEG at the sensor level without applying movement compensation techniques, or without at least checking that limited head displacements occurred between runs. Note however that trial averaging may be performed on the source times series of the MEG or EEG generators. In this latter situation, typical geometrical normalization techniques such as those used in fMRI studies need to be applied across subjects and are now a more consistent part of the MEG/EEG analysis pipeline.
Once proper averaging has been completed, measures can be taken on ERP/ERF components. Components are defined as waveform elements that emerge from the baseline of the recordings. They may be characterized in terms of e.g., relative latency, topography, amplitude and duration with respect to baseline or a specific test condition. Once again, the ERP/ERF literature is immense and cannot be summarized in these lines. Multiple reviews and textbooks are available and describe in great details the specificity and sensitivity of event-related components.
The limits of the approach
Phase-locked ERP/ERF components capture only the part of task-related brain responses that repeat consistently in latency and phase with respect to an event. One might however question the physiological origins and relevance of such components in the framework of oscillatory cell assemblies, as a possible mechanism ruling most basic electrophysiological processes (Gray, König, Engel, & Singer, 1989, Silva, 1991, David & Friston, 2003, Vogels, Rajan, & Abbott, 2005). This has lead to a fair amount of controversy, whereby evoked components would rather be considered as artifacts of event-related, induced phase resetting of ongoing brain rhythms, mostly in the alpha frequency range ([8,12]Hz) (Makeig et al.., 2002). Under this assumption, epoch averaging would only provide a secondary and poorly specific window on brain processes: this is certainly quite severe.
Indeed, event-related amplitude modulations – hence not phase effects – of ongoing alpha rhythms have been reported as major contributors to the slower event-related components captured by ERP/ERF’s (Mazaheri & Jensen, 2008). Some authors associate these modulations of event-related amplitudes to local enhancements/reductions of event-related synchronization/desynchronization (ERS/ERD) within cell assemblies. The underlying assumption is that as the activity of more cells tends to be synchronized, the net ensemble activity will build up to an increase in signal amplitude (Pfurtscheller & Silva, 1999).
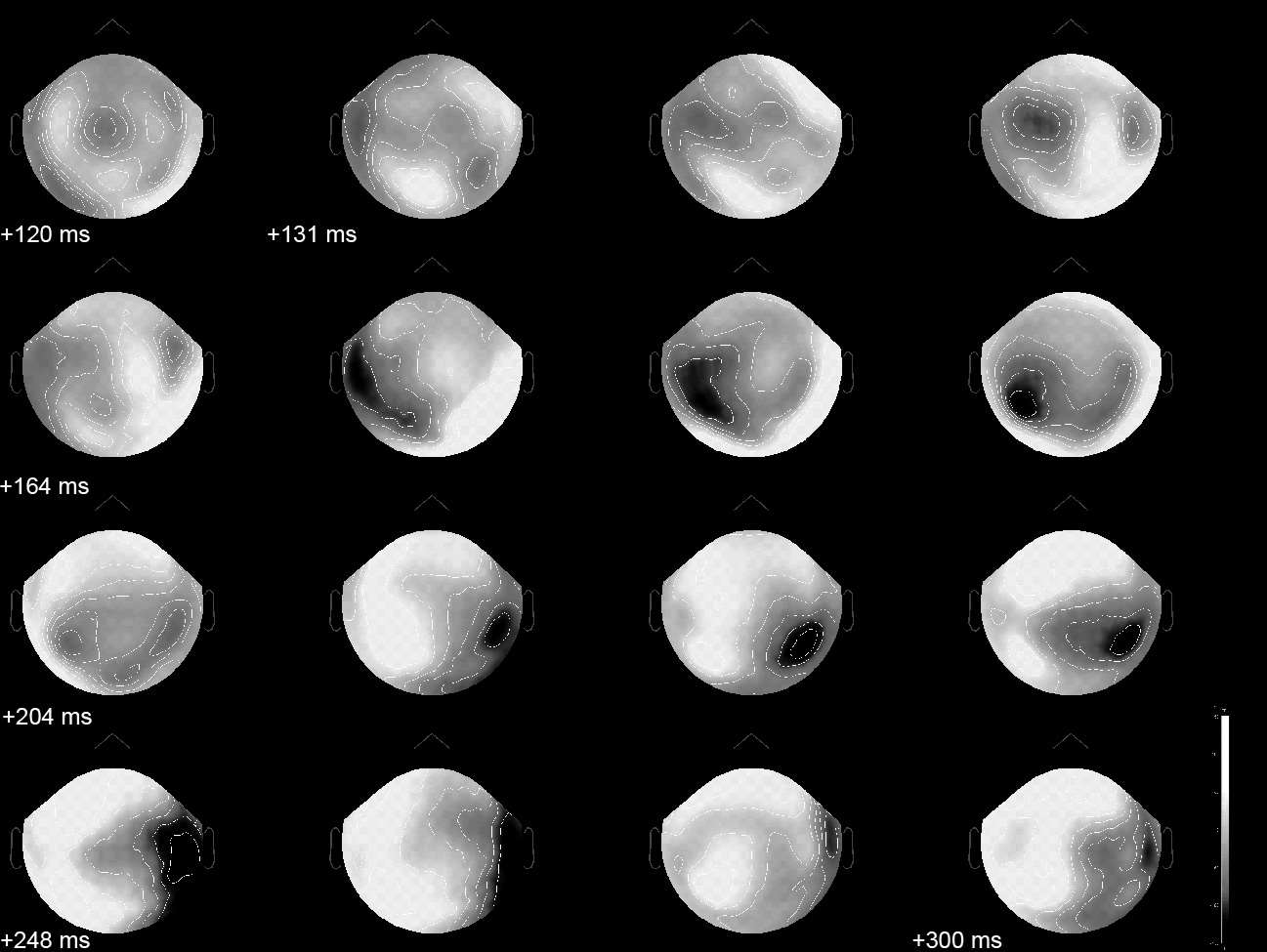
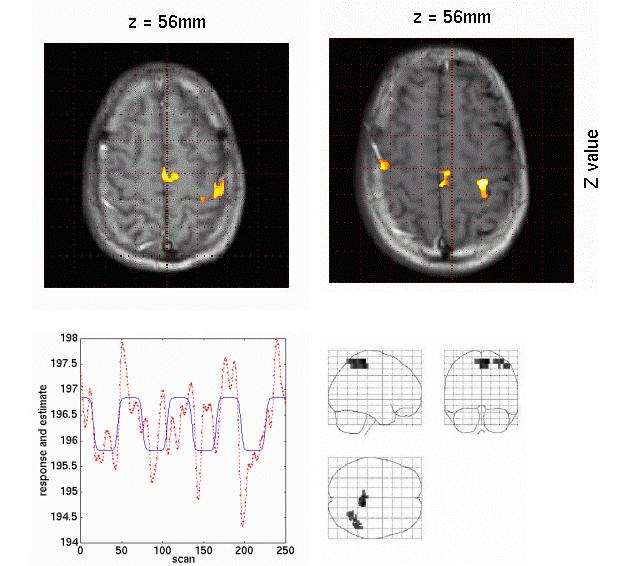
Event-related, evoked MEG surface data in a visual oddball RSVP paradigm. The data was interpolated between sensors and projected on a flattened version of the MEG channel array. Shades of gray represent the inward and outward magnetic fields picked-up outside the head during the [120,300] ms time interval following the presentation of the target face object. The spatial distribution of magnetic fields over the sensor array is usually relatively smooth and reveals some characteristic shape patterns that indicate that brain activity is rapidly changing and propagating during the time window. A much clearer insight can be provided by source imaging.
Electromagnetic Neural Source Imaging
Predicting the electromagnetic fields produced by an elementary source model at a given sensor array requires another modeling step, which concerns a large part of the MEG/EEG literature. Indeed, MEG/EEG ‘head modeling’ studies the influence of the head geometry and electromagnetic properties of head tissues on the magnetic fields and electrical potentials measured outside the head.
Given a model of neural currents, the physics of MEG/EEG are ruled by the theory of electrodynamics (Feynman, 1964), which reduces in MEG to Maxwell’s equations, and to Ohm’s law in EEG, under quasistatic assumptions. These latter consider that the propagation delay of the electromagnetic waves from brain sources to the MEG/EEG sensors is negligible. The reason is the relative proximity of MEG/EEG sensors to the brain with respect to the expected frequency range of neural sources (up to 1KHz) (Hämäläinen et al., 1993). This is a very important, simplifying assumption, which has immediate consequences on the computational aspects of MEG/EEG head modeling.
Indeed, the equations of electro and magnetostatics determine that there exist analytical, closed-form solutions to MEG/EEG head modeling when the head geometry is considered as spherical. Hence, the simplest, and consequently by far most popular model of head geometry in MEG/EEG consists of concentric spherical layers: with one sphere per major category of head tissue (scalp, skull, cerebrospinal fluid and brain).
The spherical head geometry has further attractive properties for MEG in particular. Quite remarkably indeed, spherical MEG head models are insensitive to the number of shells and their respective conductivity: a source within a single homogeneous sphere generates the same MEG fields as when located inside a multilayered set of concentric spheres with different conductivities. The reason for this is that conductivity only influences the distribution of secondary, volume currents that circulate within the head volume and which are impressed by the original primary neural currents. The analytic formulation of Maxwell’s equations in the spherical geometry shows that these secondary currents do not generate any magnetic field outside the volume conductor (Sarvas, 1987). Therefore in MEG, only the location of the center of the spherical head geometry matters. The respective conductivity and radius of the spherical layers have no influence on the measured MEG fields. This is not the case in EEG, where both the location, radii and respective conductivity of each spherical shell influence the surface electrical potentials.
This relative sensitivity to tissue conductivity values is a general, important difference between EEG and MEG.
A spherical head model can be optimally adjusted to the head geometry, or restricted to regions of interest e.g., parieto-occipital regions for visual studies. Geometrical registration to MRI anatomical data improves the adjustment of the best-fitting sphere geometry to an individual head.
Another remarkable consequence of the spherical symmetry is that radially oriented brain currents produce no magnetic field outside a spherically symmetric volume conductor. For this reason, MEG signals from currents generated within the gyral crest or sulcal depth are attenuated, with respect to those generated by currents flowing perpendicularly to the sulcal walls. This is another important contrast between MEG and EEG’s respective sensitivity to source orientation (Hillebrand & Barnes, 2002).
Finally, the amplitude of magnetic fields decreases faster than electrical potentials’ with the distance from the generators to the sensors. Hence it has been argued that MEG is less sensitive to mesial and subcortical brain structures than EEG. Experimental and modeling efforts have shown however that MEG can detect neural activity from deeper brain regions (Tesche, 1996, Attal et al.., 2009).
Though spherical head models are convenient, they are poor approximations of the human head shape, which has some influence on the accuracy of MEG/EEG source estimation (Fuchs, Drenckhahn, Wischmann, & Wagner, 1998). More realistic head geometries have been investigated and all require solving Maxwell’s equations using numerical methods. Boundary Element (BEM) and Finite Element (FEM) methods are generic numerical approaches to the resolution of continuous equations over discrete space. In MEG/EEG, geometric tessellations of the different envelopes forming the head tissues need to be extracted from the individual MRI volume data to yield a realistic approximation of their geometry.
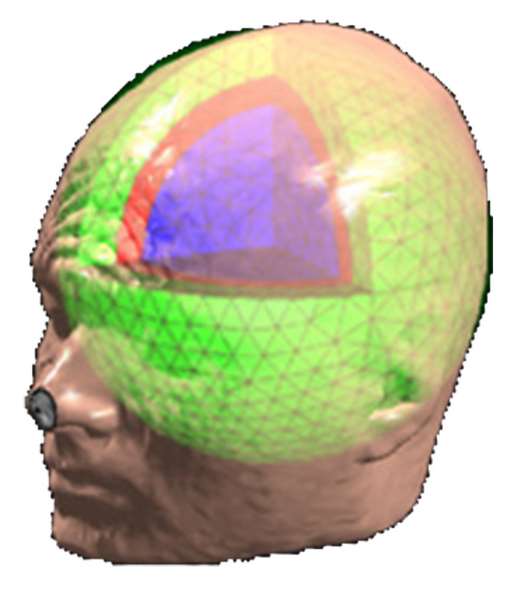
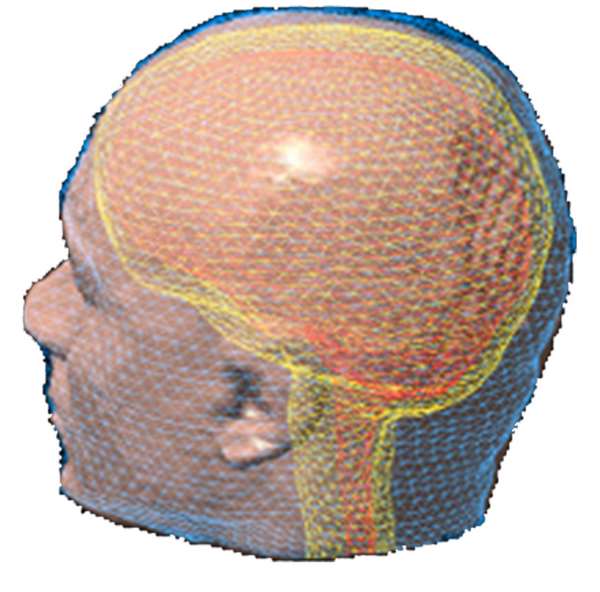
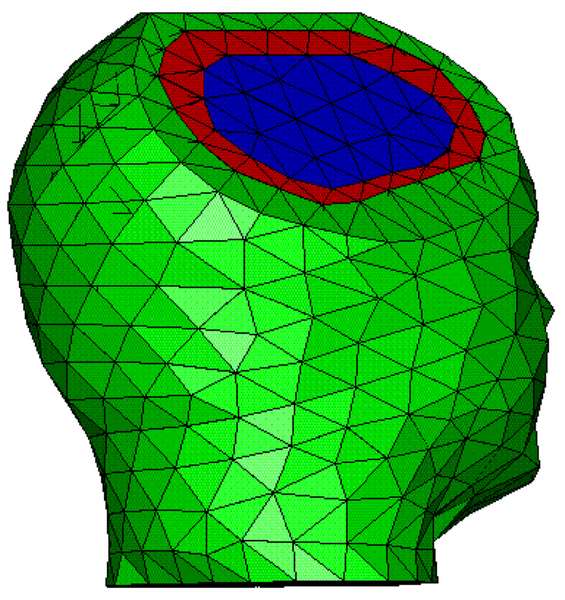
Three approaches to MEG/EEG head modeling: (a) Spherical approximation of the geometry of head tissues, with analytical solution to Maxwell’s and Ohm’s equations; (b) Tessellated surface envelopes of head tissues obtained from the segmentation of MRI data; (c) An alternative to (b) using volume meshes – here built from tetrahedra. In both (b) and (c) Maxwell’s and Ohm’s equations need to be solved using numerical methods: BEM and FEM, respectively.
In BEM, the conductivity of tissues is supposed to be homogeneous and isotropic within each envelope. Therefore, each tissue envelope is delimited using surface boundaries defined over a triangulation of each of the segmented envelopes obtained from MRI.
FEM assumes that tissue conductivity may be anisotropic (such as the skull bone and the white matter), therefore the primary geometric element needs to be an elementary volume, such as a tetrahedron (Marin, Guerin, Baillet, Garnero, & Meunier, 1998).
The main obstacle to a routine usage of BEM, and more pregnantly of FEM, is the surface or volume tessellation phase. Because the head geometry is intricate and not always well-defined from conventional MRI due to signal drop-outs and artifacts, automatic segmentation tools sometimes fail to identify some important tissue structures. The skull bone for instance, is invisible on conventional T1-weighted MRI. Some image processing techniques however can estimate the shape of the skull envelope from high-quality T1-weighted MRI data (Dogdas, Shattuck, & Leahy, 2005). However, the skull bone is a highly anisotropic structure, which is difficult to model from MRI data. Recent progress using MRI diffusion-tensor imaging (DTI) helps reveal the orientation of major white fiber bundles, which is also a major source of conductivity anisotropy (Haueisen et al.., 2002).
Computation times for BEM and FEM remain extremely long (several hours on a conventional workstation), and are detrimental to rapid access to source localization following data acquisition. Both algorithmic (Huang, Mosher, & Leahy, 1999, Kybic, Clerc, Faugeras, Keriven, & Papadopoulo, 2005) and pragmatic (Ermer, Mosher, Baillet, & Leah, 2001, Darvas, Ermer, Mosher, & Leahy, 2006) solutions to this problem have however been proposed to make realistic head models more operational. They are available in some academic software packages.
Finally, let us close this section with an important caveat: Realistic head modeling is bound to the correct estimation of tissues conductivity values. Though solutions for impedance tomography using MRI (Tuch, Wedeen, Dale, George, & Belliveau, 2001) and EEG (Goncalves et al.., 2003) have been suggested, they remain to be matured before entering the daily practice of MEG/EEG. So far, conductivity values from ex-vivo studies are conventionally integrated in most spherical and realistic head models (Geddes & Baker, 1967).
MEG/EEG Source Modeling for Localization and Imaging of Brain Activity
The localization approach to MEG/EEG source estimation considers that brain activity at any time instant is generated by a relatively small number (a handful, at most) of brain regions. Each source is therefore represented by an elementary model, such as an ECD, that captures local distributions of neural currents. Ultimately, each elementary source is back projected or constrained to the subject’s brain volume or an MRI anatomical template, for further interpretation. In a nutshell, localization models are essentially compact, in terms of number of generators involved and their surface extension (from point-like to small cortical surface patches).
The alternative imaging approaches to MEG/EEG source modeling were originally inspired by the plethoric research in image restoration and reconstruction in other domains (early digital imaging, geophysics, and other biomedical imaging techniques). The resulting image source models do not yield small sets of local elementary models but rather the distribution of ‘all’ neural currents. This results in stacks of images where brain currents are estimated wherever elementary current sources had been previously positioned. This is typically achieved using a dense grid of current dipoles over the entire brain volume or limited to the cortical gray matter surface. These dipoles are fixed in location and generally, orientation, and are homologous to pixels in a digital image. The imaging procedure proceeds to the estimation of the amplitudes of all these elementary currents at once. Hence contrarily to the localization model, there is no intrinsic sense of distinct, active source regions per se. Explicit identification of activity issued from discrete brain regions usually necessitates complementary analysis, such as empirical or inference-driven amplitude thresholding, to discard elementary sources of non-significant contribution according to the statistical appraisal. In that respect, MEG/EEG source images are very similar in essence to the activation maps obtained in fMRI, with the benefit of time resolution however.
Inverse modeling: the localization (a) vs. imaging (b) approaches. Source modeling through localization consists in decomposing the MEG/EEG generators in a handful of elementary source contributions; the simplest source model in this situation being the equivalent current dipole (ECD). This is illustrated here from experimental data testing the somatotopic organization of primary cortical representations of hand fingers. The parameters of the single ECD have been adjusted on the [20, 40] ms time window following stimulus onset. The ECD was found to localize along the contralateral central sulcus as revealed from the 3D rendering obtained after the source location has been registered to the individual anatomy. In the imaging approach, the source model is spatially-distributed using a large number of ECD’s. Here, a surface model of MEG/EEG generators was constrained to the individual brain surface extracted from T1-weighted MR images. Elemental source amplitudes are interpolated onto the cortex, which yields an image-like distribution of the amplitudes of cortical currents.
Source imaging approaches have developed in parallel to the other techniques discussed above. Imaging source models consist of distributions of elementary sources, generally with fixed locations and orientations, which amplitudes are estimated at once. MEG/EEG source images represent estimations of the global neural current intensity maps, distributed within the entire brain volume or constrained at the cortical surface.
Source image supports consist of either a 3D lattice of voxels or of the nodes of the triangulation of the cortical surface. These latter may be based on a template, or preferably obtained from the subject’s individual MRI and confined to a mask of the grey matter. Multiple academic software packages perform the necessary segmentation and tessellation processes from high-contrast T1-weighted MR image volumes.

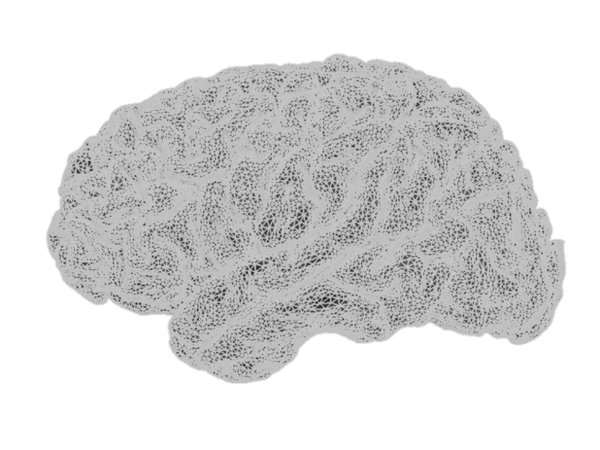
The cortical surface, tessellated at two resolutions, using: (top row) 10,034 vertices (20,026 triangles with 10 mm2 average surface area) and (bottom row) 79,124 vertices (158,456 triangles with 1.3 mm2 average surface area).
As discussed elsewhere in these pages, the cortically-constrained image model derives from the assumption that MEG/EEG data originates essentially from large cortical assemblies of pyramidal cells, with currents generated from post-synaptic potentials flowing orthogonally to the local cortical surface. This orientation constraint can either be strict (Dale & Sereno, 1993) or relaxed by authorizing some controlled deviation from the surface normal (Lin, Belliveau, Dale, & Hamalainen, 2006).
In both cases, reasonable spatial sampling of the image space requires several thousands (typically ~10000) of elementary sources. Consequently, though the imaging inverse problem consists in estimating only linear parameters, it is dramatically underdetermined.
Just like in the context of source localization where e.g., the number of sources is a restrictive prior as a remedy to ill-posedness, imaging models need to be complemented by a priori information. This is properly formulated with the mathematics of regularization as we shall now briefly review.
Adding priors to the imaging model can be adequately formalized in the context of Bayesian inference where solutions to inverse modeling satisfy both the fit to observations – given some probabilistic model of the nuisances – and additional priors. From a parameter estimation perspective, the maximum of the a posteriori probability distribution of source intensity, given the observations could be considered as the ‘best possible model’. This maximum a posteriori (MAP) estimate has been extremely successful in the digital image restoration and reconstruction communities. (Geman & Geman, 1984) is a masterpiece reference of the genre. The MAP is obtained in Bayesian statistics through the optimization of the mixture of the likelihood of the noisy data – i.e., of the predictive power of a given source model – with the a priori probability of a given source model.
We do not want to detail the mathematics of Bayesian inference any further here as this would reach outside the objectives of these pages. Specific recommended further reading includes (Demoment, 1989), for a Bayesian discussion on regularization and (Baillet, Mosher, & Leahy, 2001), for an introduction to MEG/EEG imaging methods, also in the Bayesian framework.
From a practical standpoint, the priors on the source image models may take multiple faces: promote current distributions with high spatial and temporal smoothness, penalize models with currents of unrealistic, non-physiologically plausible amplitudes, favor the adequation with an fMRI activation maps, or prefer source image models made of piecewise homogeneous active regions, etc. An appealing benefit from well-chosen priors is that it may ensure the uniqueness of the optimal solution to the imaging inverse problem, despite its original underdeterminacy.
Because relevant priors for MEG/EEG imaging models are plethoric, it is important to understand that the associated source estimation methods usually belong to the same technical background. Also, the selection of image priors can be seen as arbitrary and subjective an issue as the selection of dipoles in the source localization techniques we have reviewed previously. Comprehensive solutions for this model selection issue are now emerging and will be briefly reviewed further below.
The free parameters of the imaging model are the amplitudes of the elementary source currents distributed on the brain’s geometry. The non-linear parameters (e.g., the elementary source locations) now become fixed priors as provided by anatomical information. The model estimation procedure and the very existence of a unique solution strongly depend on the mathematical nature of the image prior.
A widely-used prior in the field of image reconstruction considers that the expected source amplitudes be as small as possible on average. This is the well-described minimum-norm (MN) model. Technically speaking, we are referring to the L2-norm; the objective cost function ruling the model estimation is quadratic in the source amplitudes, with a unique analytical solution (Tarantola, 2004). The computational simplicity and uniqueness of the MN model has been very attractive in MEG/EEG early on (Wang et al.., 1992).
The basic MN estimate is problematic though as it tends to favor the most superficial brain regions (e.g., the gyral crowns) and underestimate contributions from deeper source areas (such as sulcal fundi) (Fuchs, Wagner, Köhler, & Wischmann, 1999).
As a remedy, a slight alteration of the basic MN estimator consists in weighting each elementary source amplitude by the inverse of the norm of its contribution to sensors. Such depth weighting yields a weighted MN (WMN) estimate, which still benefits from uniqueness and linearity in the observations as the basic MN (Lin, Witzel, et al.., 2006).
Despite their robustness to noise and simple computation, it is relevant to question the neurophysiological validity of MN priors. Indeed – though reasonably intuitive – there is no evidence that neural currents would systematically match the principle of minimal energy. Some authors have speculated that a more physiologically relevant prior would be that the norm of spatial derivatives (e.g., surface or volume gradient or Laplacian) of the current map be minimized (see LORETA method in (Pascual-Marqui, Michel, & Lehmann, 1994)). As a general rule of thumb however, all MN-based source imaging approaches overestimate the smoothness of the spatial distribution of neural currents. Quantitative and qualitative empirical evidence however demonstrate spatial discrimination of reasonable range at the sub-lobar brain scale (Darvas, Pantazis, Kucukaltun-Yildirim, & Leahy, 2004, Sergent et al.., 2005).
Most of the recent literature in regularized imaging models for MEG/EEG consists in struggling to improve the spatial resolution of the MN-based models (see (Baillet, Mosher, & Leahy, 2001) for a review) or to reduce the degree of arbitrariness involved in selected a generic source model a priori (Mattout, Phillips, Penny, Rugg, & Friston, 2006, Stephan, Penny, Daunizeau, Moran, & Friston, 2009). This results in notable improvements in theoretical performances, though with higher computational demands and practical optimization issues.
As a general principle, we are facing the dilemma of knowing that all priors about the source images are certainly abusive, hence that the inverse model is approximative, while hoping it is just not too approximative. This discussion is recurrent in the general context of estimation theory and model selection as we shall discuss in the next section.
![Distributed source imaging of the [120,300] ms time interval following the presentation of the target face object](/-/media/MCW/Departments/Magnetoencephalography-Program/figure13.jpg)
Distributed source imaging of the [120,300] ms time interval following the presentation of the target face object in the visual RSVP oddball paradigm described before. The images show a slightly smoothed version of one participant’s cortical surface. Colors encode the contrast of MEG source amplitudes between responses to target versus control faces. Visual responses are detected by 120ms and rapidly propagate anteriorly. By 250 ms onwards, strong anterior mesial responses are detected in the cingular cortex. These latter are the main contributors of the brain response to target detection.
Appraisal of MEG/EEG Source Models
Questions like: ‘How different is the dipole location between these two experimental conditions?’ and ‘Are source amplitudes larger in such condition that in a control condition?’ belong to statistical inference from experimental data. The basic problem of interest here is hypothesis testing, which is supposed to potentially invalidate a model under investigation. Here, the model must be understood at a higher hierarchical level than when talking about e.g., an MEG/EEG source model. It is supposed to address the neuroscience question that has motivated data acquisition and the experimental design (Guilford, P., & Fruchter, B., 1978).
In the context of MEG/EEG, the population samples that will support the inference are either trials or subjects, for hypothesis testing at the individual and group levels, respectively.
As in the case of the estimation of confidence intervals, both parametric and non-parametric approaches to statistical inference can be considered. There is no space here for a comprehensive review of tools based on parametric models. They have been and still are extensively studied in the fMRI and PET communities – and recently adapted to EEG and MEG (Kiebel, Tallon-Baudry, & Friston, 2005) – and popularized with software toolboxes such as SPM (K. Friston, Ashburner, Kiebel, Nichols, & Penny, 2007).
Non-parametric approaches such as permutation tests have emerged for statistical inference applied to neuroimaging data (Nichols & Holmes, 2002, Pantazis, Nichols, Baillet, & Leahy, 2005). Rather than applying transformations to the data to secure the assumption of normally-distributed measures, non-parametric statistical tests take the data as they are and are robust to departures from normal distributions.
In brief, hypothesis testing forms an assumption about the data that the researcher is interested about questioning. This basic hypothesis is called the null hypothesis, H0, and is traditionally formulated to translate no significant finding in the data e.g., ‘There are no differences in the MEG/EEG source model between two experimental conditions’. The statistical test will express the significance of this hypothesis and evaluate the probability that the statistics in question would be obtained just by chance. In other words, the data from both conditions are interchangeable under the H0 hypothesis. This is literally what permutation testing does. It computes the sample distribution of estimated parameters under the null hypothesis and verifies whether a statistics of the original parameter estimates was likely to be generated under this law.
We shall now review rapidly the principles of multiple hypotheses testing from the same sample of measurements, which induces errors when multiple parameters are being tested at once. This issue pertains to statistical inference both at the individual and group levels. Samples therefore consist of repetitions (trials) of the same experiment in the same subject, or of the results from the same experiment within a set of subjects, respectively. This distinction is not crucial at this point. We shall however point at the issue of spatial normalization of the brain across subjects either by applying normalization procedures (Ashburner & Friston, 1997) or by the definition of a generic coordinate system onto the cortical surface (Fischl, Sereno, & Dale, 1999, Mangin et al.., 2004).
The outcome of a test will evaluate the probability p that the statistics computed from the data samples be issued from complete chance as expressed by the null hypothesis. The investigator needs to fix a threshold on p a priori, above which H0 cannot be rejected, thereby corroborating H0. Tests are designed to be computed once from the data sample so that the error – called the type I error – consisting in accepting H0 while it is invalid stays below the predefined p-value.
If the same data sample is used several times for several tests, we multiply the chances that we commit a type I error. This is particularly critical when running tests on sensor or source amplitudes of an imaging model as the number of tests is on the order of 100 and even 10,000, respectively. In this latter case, a 5% error over 10,000 tests is likely to generate 500 occurrences of false positives by wrongly rejecting H0. This is obviously not desirable and this is the reason why this so-called family-wise error rate (FWER) should be kept under control.
Parametric approaches to address this issue have been elaborated using the theory of random fields and have gained tremendous popularity through the SPM software (K. Friston et al.., 2007). These techniques have been extended to electromagnetic source imaging but are less robust to departure from normality than non-parametric solutions. The FWER in non parametric testing can be controlled by using e.g., the statistics of the maximum over the entire source image or topography at the sensor level (Pantazis et al.., 2005).
The emergence of statistical inference solutions adapted to MEG/EEG has brought electromagnetic source localization and imaging to a considerable degree of maturity that is quite comparable to other neuroimaging techniques. Most software solutions now integrate sound solutions to statistical inference for MEG and EEG data, and this is a field that is still growing rapidly.
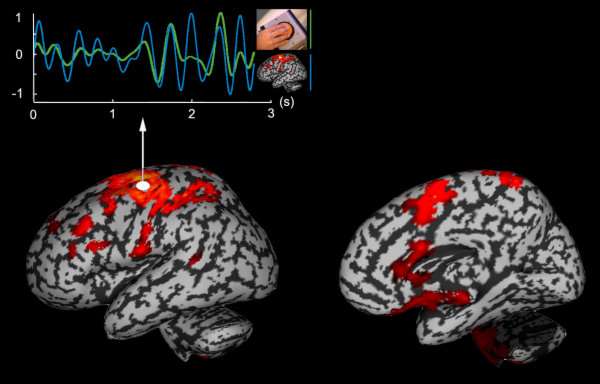
MEG functional connectivity and statistical inference at the group level illustrated: Jerbi et al. (2007) have revealed a cortical functional network involved in hand movement coordination at low frequency (4Hz). The statistical group inference first consisted on fitting for each trial in the experiment, a distributed source model constrained to the individual anatomy of each of the 14 subjects involved. The brain area with maximum coherent activation with instantaneous hand speed was identified within the contralateral sensorimotor area (white dot). The traces at the top illustrate excellent coherence in the [3,5]Hz range between these measurements (hand speed in green and M1 motor activity in blue). Secondly, the search for brain areas with activity in significant coherence with M1 revealed a larger distributed network of regions. All subjects were coregistered to a brain surface template in Talairach normalized space with the corresponding activations interpolated onto the template surface. A non-parametric t-test contrast was completed using permutations between rest and task conditions (p<0.01).
We have discussed how fitting dipoles to a data time segment may be quite sensitive to initial conditions and therefore, subjective. Similarly, imaging source models suggest that each brain location is active, potentially. It is therefore important to evaluate the confidence one might acknowledge to a given model. In other words, we are now looking for error bars that would define a confidence interval about the estimated values of a source model.
Signal processors have developed a principled approach to what they have coined as ‘detection and estimation theories’ (Kay, 1993). The main objective consists in understanding how certain one can be about the estimated parameters of a model, given a model for the noise in the data. The basic approach consists in considering the estimated parameters (e.g., source locations) as distributed through random variables. Parametric estimation of error bounds on the source parameters consists in estimating their bias and variance.
Bias is an estimation of the distance between the true value and the expectancy of estimated parameter values due to perturbations. The definition of variance follows immediately. Cramer-Rao lower bounds (CRLB) on the estimator’s variance can be explicitly computed using an analytical solution to the forward model and given a model for perturbations (e.g., with distribution under a normal law). In a nutshell, the tighter the CRLB, the more confident one can be about the estimated values. (J. C. Mosher, Spencer, Leahy, & Lewis, 1993) have investigated this approach using extensive Monte-Carlo simulations, which evidenced a resolution of a few millimeters for single dipole models. These results were later confirmed by phantom studies (Leahy, Mosher, Spencer, Huang, & Lewine, 1998, Baillet, Riera, et al.., 2001). CRLB increased markedly for two-dipole models, thereby demonstrating their extreme sensitivity and instability.
Recently, non-parametric approaches to the determination of error bounds have greatly benefited from the commensurable increase in computational power. Jackknife and bootstrap techniques proved to be efficient and powerful tools to estimate confidence intervals on MEG/EEG source parameters, regardless of the nature of perturbations and of the source model.
These techniques are all based on data resampling approaches and have proven to be exact and efficient when a large-enough number of experimental replications are available (Davison & Hinkley, 1997). This is typically the case in MEG/EEG experiments where protocols are designed on multiple trials. If we are interested e.g., in knowing about the confidence interval on a source location in a single-dipole model from evoked averaged data, the bootstrap will generate a large number (typically >500) of surrogate average datasets, by randomly choosing trials from the original set of trials and averaging them all together. Because the trial selection is random and from the complete set of trials, the corresponding sample distribution of the estimated parameter values is proven to converge toward the true distribution. A pragmatic approach to the definition of a confidence interval thereby consists in identifying the interval containing e.g., 95% of the resampled estimates ((Baryshnikov, Veen, & Wakai, 2004, Darvas et al.., 2005, McIntosh & Lobaugh, 2004)).
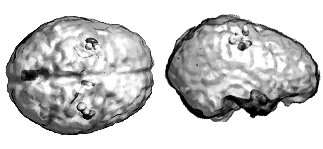
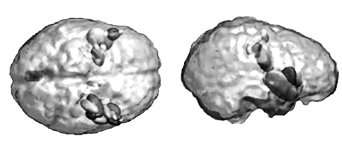
The bootstrap procedure yields non parametric estimates of confidence intervals on source parameters. This is illustrated here with data from a study of the somatotopic cortical representation of hand fingers. Ellipsoids represent the resulting 95% confidence intervals on the location of the ECD, as a model of the 40 ms (a) and 200 ms (b) brain response following hand finger stimulation. Ellipsoid gray levels encode for the stimulated fingers. While in (a) the respective confidence ellipsoids do not overlap between fingers, they considerably increase in volume for the secondary responses in (b), thereby demonstrating that a single ECD is not a proper model of brain currents at this later latency. Note similar evaluations may be drawn from imaging models using the same resampling methodology.
These considerations naturally lead us to statistical inference, which questions hypothesis testing.
Introduction to Functional Brain Imaging
In essence, the physiological changes captured by these techniques fluctuate within a typical time scale of several hundreds of milliseconds at best, which makes them excellent at mapping the regions involved in task performance or resting-states (Fox & Raichle, 2007), but incapable of resolving the flow of rapid brain activity that unfolds with time. Metaphorically speaking, metabolic and hemodynamic techniques perform as very sensitive cameras that are able to capture low-intensity signals using long aperture durations, hence a sluggish temporal resolution. This basic limitation has become salient as new neuroscience questions emerge to investigate the brain as an ensemble of complex networks that form, reshape and flush information dynamically (Varela, Lachaux, Rodriguez, & Martinerie, 2001, Sergent & Dehaene, 2004, Werner, 2007).
An additional, though seemingly minor, limitation of hemodynamic (i.e. MRI-based) modalities consist in their operational environment: most scanners are installed in hospitals, with typically limited access time but more importantly, necessitate that subjects lie supine in a narrow tunnel, with loud noises generated by the acquisition processes. Such non-ecological environment is certainly detrimental to the subject’s comfort and therefore, limits the possibilities in terms of stimulus presentation and real-time interaction with participants, which are central issues in e.g., Social Neuroscience studies or research and clinical sessions with children.
These pages therefore describe how Electroencephalography (EEG) and Magnetoencephalography (MEG) offer complementary alternatives to typical neuroimaging studies in that respect. We will briefly review the basic, though very rich, methods of sensor data analysis, which focus of the chronometry of so-called brain events. We will further emphasize how MEG and EEG may be utilized as neuroimaging techniques, that is, how they are capable to map dynamic brain activity and functional connectivity with fair spatial resolution and unique rapid time scales. EEG recordings have been made possible in the MRI environment, therefore leading to multimodal data acquisition and analysis (Laufs, Daunizeau, Carmichael, & Kleinschmidt, 2008). This has brought up interesting discussions and results on e.g., rapid phenomena such as epileptiform events and the electrophysiological counterpart of BOLD resting-state fluctuations (Mantini, Perrucci, Gratta, Romani, & Corbetta, 2007). MEG and EEG data acquired with high-density sensor arrays also stand by themselves as functional neuroimaging techniques: this is the realm of electromagnetic brain mapping (Salmelin & Baillet, 2009). It is indeed interesting to note that MEG instruments are being delivered to prominent functional neuroimaging clinical and research centers who are willing to expand their investigations beyond the static, functional cartography of the brain. These pages offer a pragmatic review of this rapidly evolving field.
Scenarios of Most Typical MEG/EEG Sessions
The time dimension accessible to MEG/EEG offers some considerable variety in the design of experimental paradigms for testing virtually any basic neuroscience hypothesis. Managing this new dimension is sometimes puzzling for investigators with an fMRI neuroimaging background as MEG/EEG allows to manipulate experimental parameters and presentations in the real time of the brain, not at the much slower pace of hemodynamic responses.
In a nutshell, MEG/EEG experimental design is conditioned on the type of brain responses of foremost interest to the investigator: evoked, induced or sustained. The most common experimental design by far is the interleaved presentation of transient stimuli representing multiple conditions to be tested. In this design, stimuli of various categories and valences (pictures, sounds, somatosensory electric pulses or air puffs, or their combination, etc.) are presented in sequence with various inter stimulus interval (ISI) durations. ISIs are typically much shorter than in fMRI paradigms and range from a few tens of milliseconds to a few seconds.
The benefit of the high temporal resolution of MEG/EEG is twofold in that respect:
- It allows to detect and categorize the chronometry of effects occurring after stimulus presentation (evoked or induced brain responses), and
- It provides leverage to the investigator to manipulate the timing of stimulus presentation to emphasize the very dynamics of brain processes.
The first category of experimental designs is the most typical and has a long history of scientific investigations in the characterization of the specificity of certain brain responses to certain stimulus categories (sounds, faces, words, novelty detection, etc.) as we shall discuss in greater details below. It consists in the serial presentation of stimuli and possibly, subject responses. These experimental events are well-separated in time and the brain activity of interest in related to the presentation of each individual event, hence an 'event-related' paradigm.
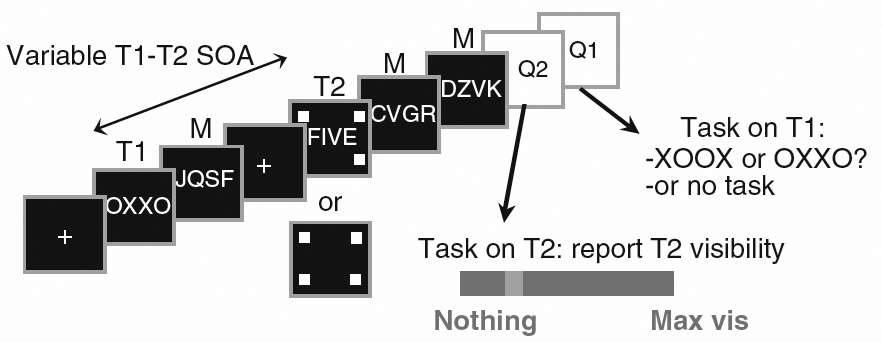
Experimental protocol and behavioral results recorded during an event-related session. T1 and T2 are two task-related stimulus objects. In this experiment, each trial consisted in a simple sequence containing five items: T1, followed by a mask (M), and T2 (which could be present or absent) followed by two successive masks. The stimulus onset asynchrony (a sub-type of ISI) between T1 and T2 could be either short (258 ms) or long (688 ms). Presentation of T2 was signaled by 4 surrounding squares. When T2 was absent, the four squares were presented on a blank screen. Each trial ended with a question on T2 (Q2: visibility scale) and, in the dual task condition, a question on T1 (Q1).
Adapted from (Sergent, Baillet & Dehaene, Timing of the brain events underlying access to consciousness during the attentional blink. Nature Neuroscience, 2005, 8, 1391-1400).
The second category of designs aims at pushing the limits of the dynamics of brain processes: a typical situation would consist in better understanding how brain processes unfold and may be conditional to a hierarchy of sequences in the treatment of stimulus information from e.g., primary sensory areas to its cognitive evaluation. This may be well exemplified by paradigms such as oddball rapid serial visual presentation (RSVP, (Kranczioch, Debener, Herrmann, & Engel, 2006)), or when investigating time-related effects such as the attentional blink (Sergent, Baillet, & Dehaene, 2005, Dux & Marois, 2009). Steady-state brain responses triggered by sustained stimulus presentations belong also to this category. Here, a stimulus with specific temporal encoding (e.g., visual pattern reversals or sound modulations at a well-defined frequency) is presented and may trigger brain responses locked to the stimulus presentation rate or some harmonics. This approach is sometimes called ‘frequency-tagging’ (of brain responses). This has lead to a rich literature of steady-state brain responses in the study of multiple brain systems (Ding, Sperling, & Srinivasan, 2006, Bohórquez & Ozdamar, 2008, Parkkonen, Andersson, Hämäläinen, & Hari, 2008, Vialatte, Maurice, Dauwels, & Cichocki, 2009) and new strategies for brain computer interfaces (see e.g., (Mukesh, Jaganathan, & Reddy, 2006)).
A typical event-related paradigm design for MEG/EEG. The experiment consists of the detection of a visual ‘oddball’. Pictures of faces are presented very rapidly to the participants every 100ms, for a duration of 50ms and an ISI of 50ms. In about 15% of the trials, a face known to the participant is presented. This is the target stimulus and the participant needs to count the number of times he/she has seen the target individual among the unknown, distracting faces. Here, the experiment consisted of 4 runs of about 200 trials, hence resulting in a total of 120 target presentations.
As a beneficial rule of thumb for stimulus presentation in MEG/EEG paradigms, it is important to randomize the ISI durations as much as possible for most paradigms, to minimize the effect of stimulus occurrence expectancy from the subjects. Indeed, this latter triggers brain activity patterns that have been well characterized in multiple EEG studies (Clementz, Barber, & Dzau, 2002, Mnatsakanian & Tarkka, 2002) and which may bias both the subsequent MEG/EEG and behavioral responses (e.g., reaction times) to stimulation.
We have already discussed the basics of EEG preparation to ensure that contact of electrodes with skin is of quality and stable.
Additional precautions should be taken for an MEG recording session as any magnetic material carried by the subject would cause major MEG artifacts. It is therefore recommended that the subject’s compatibility with MEG be rapidly checked by recording and visually inspecting their spontaneous resting activity, prior to EEG preparation and proceeding any further into the experiment. Large artifacts due to metallic and magnetic parts (coins, credit cards, some dental retainers, body piercing, bra supports, etc.) or particles (make-up, hair spray, tattoos) can be readily and visually detected as they cause major low-frequency deflections in MEG traces. They are usually emphasized with respiration and/or eye blinks and/or jaw movements.
Some causes of artifacts may not be easily circumvented: Research volunteers may have participated in an fMRI study, sometimes months before the MEG session. Previous participation to an MRI session is likely to have caused strong, long-term magnetization of e.g., dental retainers, which generally brings the MEG session to a premature close. On site demagnetization may be attempted using ‘degaussing’ techniques – usually using a conventional magnetic tape eraser, which attenuates and scrambles magnetization – with limited chances of success though.
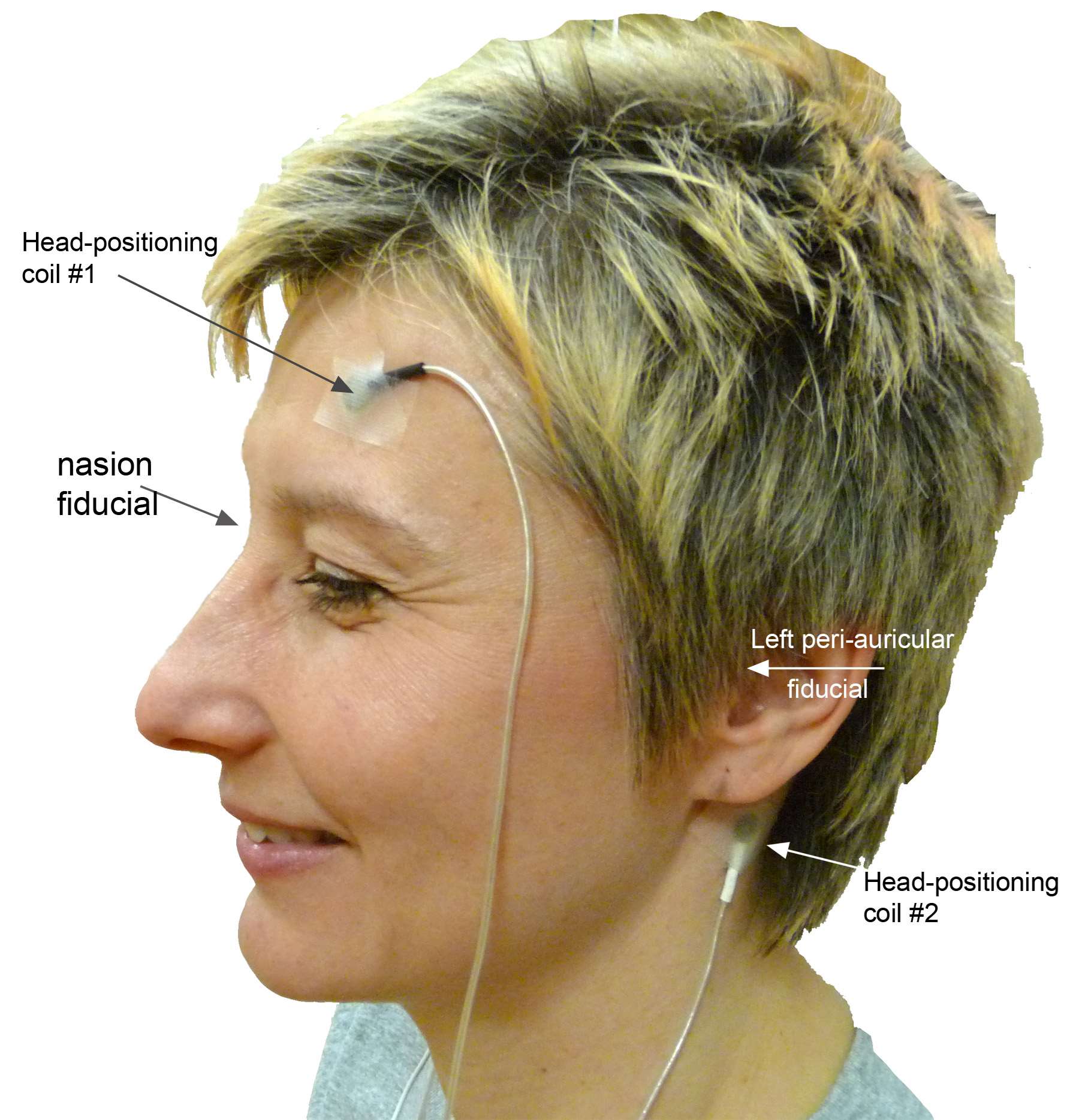
Subjects are subsequently encouraged to change to wear a gown or scrubs before completing their preparation. If EEG is recorded with MEG, electrode preparation should follow the conventional principles of good EEG practice. Additional leads for EOG, ECG, EMG may then be positioned. In state-of-the-art MEG systems, head-positioning (HPI) coils are taped to the subject’s head to detect its position with respect to the sensor array while recording. This is critical as, though head motion is not encouraged, it is very likely to occur within and in between runs, especially with young children and some patients. The HPIs drive a current at some higher (~300Hz) frequency that is readily detected by the MEG sensors at the beginning of each run. Each of the HPI coil can then be localized within seconds with millimeter accuracy. Some MEG systems - like our system at MCW - feature the possibility for continuous head-position monitoring during the very recording and off-line head movement compensation (Wehner, Hämäläinen, Mody, & Ahlfors, 2008).
Head-positioning is made possible after the locations of the HPI coils are digitized prior to sitting the subject under the MEG array (Fig. 5). The distance between HPI pairs is then checked for consistency and independently by the MEG system, which is a fundamental step in the quality control of the recordings. Noisy sensors or environment and badly secured HPI taping are sources of discrepancies between the moment of subject preparation and the actual MEG recordings and should be attended. If advanced source analysis is required, additional 3D digitization of anatomical fiducial points is necessary to ensure that subsequent registration to the subject’s MRI anatomical volume is successful and accurate (see below). A minimum of 3 fiducial points should be localized: they usually sit by the nasion and left and right peri-auricular points. To reduce ambiguity in the detection of these points in the MR volume data, they can be marked using vitamin E pills or any other solid marker that is readily visible in T1-weighted MR images, if MRI is scheduled right after the MEG session. Digitization of EEG electrode locations is also mandatory for accurate, subsequent source analysis.
Overall, about 15 minutes are required for subject preparation for an MEG-only session, which can extend up to about 45 minutes if simultaneous high-density EEG is required.
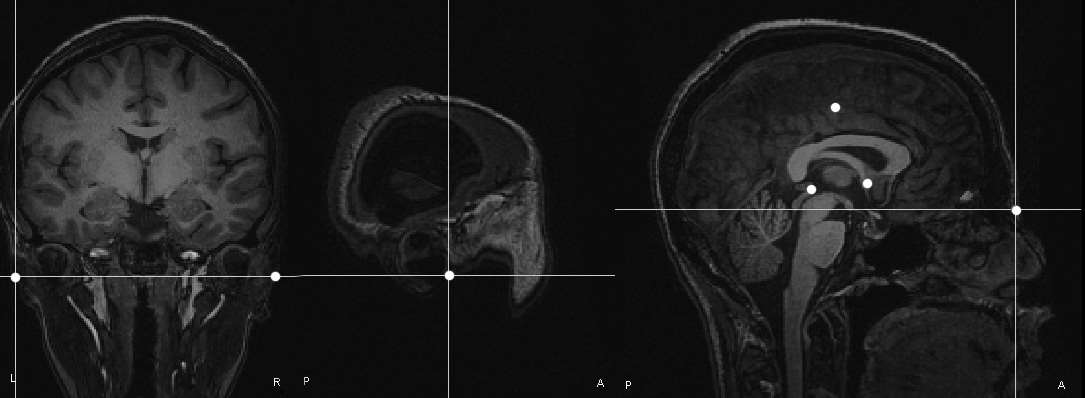
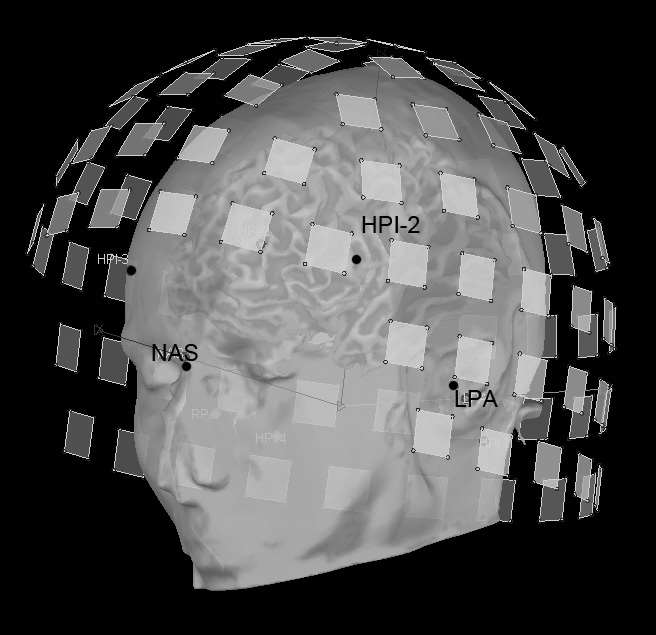
Multimodal MEG/MRI geometrical registration. (a) 3 to 5 head-positioning indicators (HPI) are taped onto the subject’s scalp. Their positions, together with 3 additional anatomical fiducials (nasion, left and right peri-auricular points (NAS, LPA and RPA, respectively)) are digitized using a magnetic pen digitizer. (b) The anatomical fiducials need to be detected and marked in the subject’s anatomical MRI volume data: they are shown as white dots in this figure, together with 3 optional, additional points defining the anterior and posterior commissures and the interhemispheric space, for the definition of Talairach coordinates. (c) These anatomical landmarks henceforth define a geometrical referential in which the MEG sensor locations and the surface envelopes of the head tissues (e.g., the scalp and brain surface, segmented from the MRI volume) are co-registered. MEG sensors are shown as squares positioned about the head. The anatomical fiducials and HPI locations are marked using dark dots.
- A typical MEG/EEG session consists of usually several runs.
- A run is a series of experimental trials.
- A trial is an experimental event whereby a stimulus has been presented to a subject, or the subject has performed a predefined action, within a certain condition of the paradigm.
Trials and runs certainly vary in duration and length depending on experimental contingencies, but it is certainly a good advice to try to keep these numbers relatively low. It is most beneficial to the subject’s comfort and vigilance to keep the duration of a run under 10 minutes, and preferably 5 minutes. Longer runs augment the participant’s fatigue, which most commonly results in more frequent eye blinks, head movements and poorer compliance to the task instructions. For the same reasons, it is not recommended that a full session lasts longer than about 2 hours. Communication with the subject is made possible at all times via two-way intercom and video monitoring.
Setting the data sampling rate is the first parameter to decide upon when starting an MEG/EEG acquisition. Most recent systems can reach up to 5KHz per channel, which is certainly doable but leads to large data files that may be cumbersome to manipulate off-line. The sampling rate parameter is critical as it conditions the span of the frequency spectrum of the data. Indeed, this latter is limited in theory to half the sampling rate, while good practice would rather consider it is limited to about one third of the sampling frequency.
A vast majority of studies target brain responses that are evoked by stimulation and revealed after trial averaging. Most of these responses have a typical half-cycle of about 20ms and above, hence a characteristic frequency of 100Hz. A sampling rate of 300 to 600Hz would therefore be a safe choice. As briefly discussed above, high-frequency oscillatory responses in the brain have however been evidenced in the somatosensory cortex and may reach up to about 900Hz (Cimatti et al.., 2007). They therefore necessitate higher sampling rates of about 3 to 5KHz.
Storage and file handling issues may arise though, as every minute of recording corresponds to about 75MB of data, sampled at 1KHz on 300 MEG and 60 EEG channels.
During acquisition, MEG and EEG operators shall proceed to basic quality controls of the recordings. So called ‘bad channels’ may be readily detected because of evident larger noise amounts in the traces, and shall be addressed (by e.g., posing more gel under the electrode or tuning the deficient MEG channel).
 Filters may be applied during the recording, though only with caution. Indeed, band-pass filters for display only are innocuous to subsequent analysis, but most MEG/EEG instruments feature filters that are applied definitely to the actual data being recorded. The investigator shall be well aware of these parameters, which may transform into roadblocks to the analysis of some components of interest in the signals. A typical example is a low-pass filter applied at 40Hz, which prohibits subsequent access to any upper frequency ranges. Notch filters are usually applied during acquisition to attenuate power line contamination at 50 or 60Hz, though without preventing possible nuisances at some harmonics. Low-pass anti-aliasing filters are generally applied by default during acquisition – before analog-to digital conversion of signals – and their cutoff frequency is conditioned to the data sampling rate: it is conventionally set to about a third of the sampling frequency.
Filters may be applied during the recording, though only with caution. Indeed, band-pass filters for display only are innocuous to subsequent analysis, but most MEG/EEG instruments feature filters that are applied definitely to the actual data being recorded. The investigator shall be well aware of these parameters, which may transform into roadblocks to the analysis of some components of interest in the signals. A typical example is a low-pass filter applied at 40Hz, which prohibits subsequent access to any upper frequency ranges. Notch filters are usually applied during acquisition to attenuate power line contamination at 50 or 60Hz, though without preventing possible nuisances at some harmonics. Low-pass anti-aliasing filters are generally applied by default during acquisition – before analog-to digital conversion of signals – and their cutoff frequency is conditioned to the data sampling rate: it is conventionally set to about a third of the sampling frequency.
As a general recommendation, it is suggested to keep filtering to the minimum required during acquisition – i.e. anti-aliasing and optionally, a high-pass filter set at about 0.3Hz to attenuate slow DC drifts, if of no interest to the experiment – because much can be performed off-line during the pre-processing steps of signal analysis, which we shall review now.
Principles of MEG and EEG
All electrical currents produce electromagnetic fields, and our body is inundated by currents of all sorts. The muscles and the heart are two well-known and strong sources of electrophysiological currents, qualified as ‘animal electricity’ by early scientists like Luigi Galvani, who were able to evidence such phenomena more than 200 years ago. The brain also sustains ionic current flows within and across cell assemblies, with neurons as the strongest generators. The architecture of the neural cell – as decomposed into dendritic branches and tree, soma and axon – conditions the paths taken by the tiny intracellular currents flowing within the cell. The relative complexity and large variety of these current pathways can be simplified by looking at the cell from some distance: indeed, these elementary currents instantaneously sum into a net primary current flow, which can be well described as a small, straight electrical dipole conducting current from a source to a sink.
Intracellular current sources are twofold in a neuron:
- Axon potentials, which generate fast discharges of currents, and
- Slower excitatory and inhibitory post-synaptic potentials (E/I PSPs), which create an electrical imbalance between the basal, apical dendritic tree and/or the cell soma.
Each of these two categories of current sources generates electromagnetic fields, which can be well captured by local electrophysiological recording techniques. The amount of current being generated by a single cell is however too small to be detected several centimeters away and outside the head. Detecting electrophysiological traces non invasively is conditioned to two main factors:
- That the architecture of the cell is propitious to give rise to a large net current, and
- That neighboring cells would drive their respective intracellular currents with a sufficient degree of group synchronization so that they build-up and reach levels detectable at some distance.
Fortunately, a great share of neural cells possesses a longitudinal geometry; these are the pyramidal cells in neocortical layers II/III and V. Also, neurons are grouped into assemblies of tightly interconnected cells. Therefore it is likely that PSPs be identically distributed across a given assembly, with the immediate benefit that they build-up efficiently to drive larger levels of currents, which in turn generate electromagnetic fields that are strong enough to be detected outside the head.
Illustration of the basic electrophysiological principles of MEG and EEG
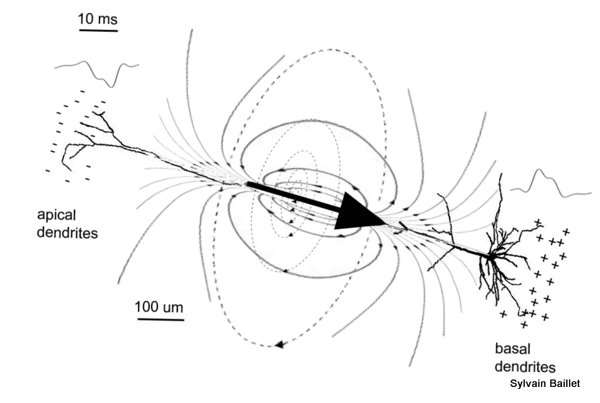
Large neural cells – just like this pyramidal neuron from cortex layer V – drive ionic electrical currents. These latter are essentially impressed by the difference in electrical potentials between the basal and apical dendrites or the cell body, which is due to a blend of excitatory and inhibitory post-synaptic potentials (PSP), which are slow (>10 ms) relatively to axon potentials firing and therefore sum-up efficiently at the scale of synchronized neural ensembles. These primary currents can be modeled using an equivalent current dipole, here represented by a large black arrow. The electrical circuit of currents is closed within the entire head volume by secondary, volume currents shown with the dark plain lines. Additionally, magnetic fields are generated by the primary and secondary currents. The magnetic field lines induced by the primary currents are shown using dash lines arranged in circles about the dipole source.
Neurons in assemblies are also likely to fire volleys of action potentials with a fair degree of synchronization. However the very short duration of each action potential firing – typically a few milliseconds – makes it very unlikely that they sufficiently overlap in time to sum-up to a massive current flow. Though smaller in amplitude, PSPs sustain with typical durations – a few tens to hundreds of milliseconds – that make temporal and amplitude overlap build-up more efficiently within the cell ensemble.
Interestingly, though PSPs were thought originally to impress only rather slow fluctuations of currents, recent experimental and modeling evidence demonstrate they are capable of also generating fast spiking activity (Murakami & Okada, 2006). One might assume that these latter may be at the origins of the very high-frequency brain oscillations (that is, up to 1KHz) captured by MEG (Cimatti et al., 2007). Indeed, mechanisms of active ion channeling within dendrites would further contribute to larger amplitudes of primary currents than initially predicted (Murakami & Okada, 2006). Hence neocortical columns consisting of as few as 50,000 pyramidal cells with an individual current density of 0.2 pA.m, would induce a net current density of 10 nA.m at the assembly level. This is the typical source strength that can be detected using MEG and EEG. Other neural cell types, such as Purkinje and stellate cells are structured with less favorable morphology and/or density than pyramidal cells. It is therefore expected that their contribution to MEG/EEG surface signals is less than neocortical regions. Published models and experimental data however report regularly on the detection of cerebellar and deeper brain activity using MEG or EEG (Tesche, 1996, Jerbi et al., 2007, Attal et al., 2009).
Cellular currents are therefore the primary contributors to MEG/EEG surface signals. These current generators operate in a conductive medium and therefore impress a secondary type of currents that circulate through the head tissues (including the skull bone) and loop back to close the electrical circuit. Consequently, it is key to the methods attempting to localize the primary current sources to discriminate these latter from the contributions of secondary currents to the measurements. Modeling the electromagnetic properties of head tissues is critical in that respect. Before reviewing this important aspect of the MEG/EEG realm, we shall first discuss the basics of MEG/EEG instrumentation.
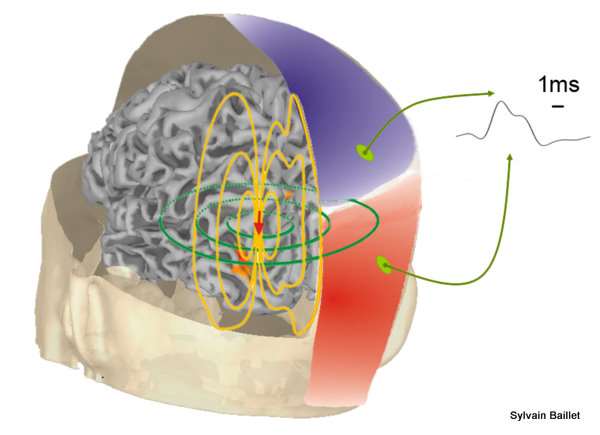
At a larger spatial scale, the mass effect of currents due to neural cells sustaining similar PSP mixtures add up locally and behave also as an current dipole (shown in red). This primary generator induces secondary currents (shown in yellow) that travel through the head tissues. They eventually reach the scalp surface where they can be detected using pairs of electrodes in EEG. Magnetic fields (in green) travel more freely within tissues and are less distorted than current flows. They can be captured using arrays of magnetometers in MEG. The distribution of blue and red colors on the scalp illustrates the continuum of magnetic and electric fields and potentials distributed at the surface of the head.
MEG and EEG Instrumentation
Heart biomagnetism was the first to be evidenced experimentally by (Baule & McFee, 1963) and Russian groups, followed in Chicago, and then in Boston, by David Cohen who contributed significant technological improvements in the late 1960s. The first low-noise MEG recording followed immediately in 1971 when Cohen reported on spontaneous oscillatory brain activity (α-rhythm, [8,12]Hz), just like Hans Berger did with EEG about 40 years before. The seminal technique was revolutionized in 1969 by the introduction of extremely sensitive current detectors developed by James Zimmerman at the Massachusetts Institute of Technology: the superconducting quantum interference devices (SQUIDs).
Once coupled to magnetic pick-up coils, these detectors are able to capture the minute variations of electrical currents induced by the flux of magnetic fields through the coil. Magnetometers – a pick-up coil paired with a current-detector – are therefore the building blocks of MEG sensing technology. Because of the very small scale of the magnetic fields generated by the brain, signal-to-noise (SNR) is a key issue in MEG technology. The superconducting sensing technology involved requires cooling at -269°C (-452F).
About 70 liters of liquid helium are necessary on a weekly basis to keep the system up to performance. Liquid nitrogen is not considered as an alternative because of the relatively higher thermal noise levels it would allow in the circuitry of current detectors. Ancillary refrigeration – e.g., using liquid nitrogen just like in MR systems – is not an option either, for the main reason that MEG sensors need to be located as close to the head as possible. Hence interleaving another container between the helium-cooled sensors and the subject would increase the distance between the sources and the measurement locations, therefore decreasing SNR. Some MEG sites currently experiment solutions to recycle some of the helium that naturally boils off from the MEG gantry. This approach is optimal if gas liquefaction equipment is available in the proximity of the MEG site. Under the best circumstances, this technique allows the recuperation and re-utilization of about 60% to 90% of the original helium volume.
Thermal insulation is obviously a challenge in terms of safety of the subject, limited boil-off rate and minimal distance to neural sources. The technology involved uses thin sheets of fiberglass separated with vacuum, which brings the pick-up coils only a couple of centimeters away from the head surface, with total comfort to the subject. The MEG instrument therefore consists of a rigid helmet containing the sensors, supplemented by a cryogenic vessel filled with liquid helium. Though the MEG equipment is obviously not ambulatory, most commercial systems can operate with subjects in seated (upright) and horizontal (supine) positions. Having these options is usually well-appreciated by investigators in terms of alternatives for stimulus presentation, subject comfort, etc.
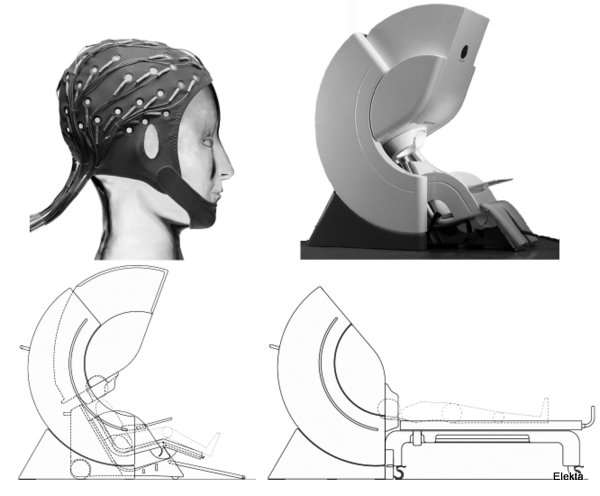
Typical MEG and EEG equipment. Top left: An elastic EEG cap with 60 electrodes. Top right: An MEG system, which can be operated both in seated upright (bottom left) and supine horizontal (bottom right) positions. EEG recordings can be performed concurrently with the MEG’s, using magnetically-compatible electrodes and wires. (Illustrations adapted courtesy of Elekta.)
Working with ultra-sensitive sensors is problematic though as these latter are very good at picking up all sorts of nuisances and electromagnetic perturbations generated by external sources. The magnetically-shielded room (MSR) has been an early major improvement to MEG sensing technology. All sites in urban areas contain the MEG equipment inside the walls of an MSR, which is built from a variety of metallic alloys. Most metals are successful at capturing radio-frequency perturbations. Mu-metal (a nickel-iron alloy) is one particular material of choice: its high magnetic permeability makes it very effective at screening external static or low-frequency magnetic fields. The attenuation of electromagnetic perturbations through the MSR walls is colossal and makes MEG recordings possible, even in noisy environments like hospitals (even near MRI suites) and in the vicinity of road traffic.
Scales of magnetic fields in a typical MEG environment (in femto- Tesla (fT), one fT is 10-15T), compared to equivalent distance measures (in meters) and relative sound pressure levels. A MEG instrument probe therefore deals with a range of environmental magnetic fields of about 10 to 12 orders of magnitude, most of which consist of nuisances and perturbations masking the brain activity.
 The magnetically-shielded room (MSR) in the course of its installation at the MCW MEG program.
The magnetically-shielded room (MSR) in the course of its installation at the MCW MEG program.